數據倉庫分層架構 原理、作用與核心價值
數據倉庫的分層架構是一種將數據處理過程進行邏輯和物理分離的設計方法,旨在構建一個清晰、高效、可維護的數據管理體系。其核心思想是通過不同的層級,對數據進行逐層加工、整合與沉淀,最終為上層的數據應用和分析提供穩定、可信的數據服務。
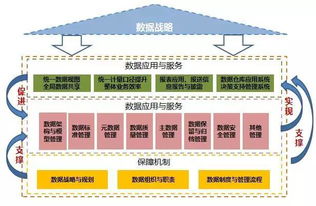
數據倉庫分層架構的核心作用
- 清晰職責分離:每一層都有明確的職責邊界,降低了系統的復雜性,便于團隊分工協作。例如,數據工程師專注于底層數據的采集與處理,數據分析師則聚焦于上層的數據分析與建模。
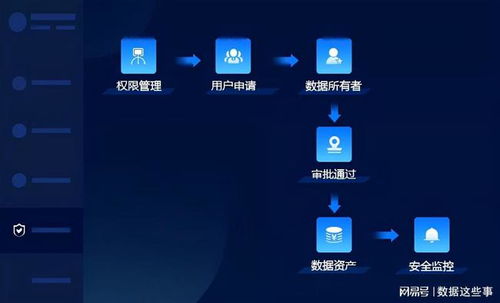
- 數據質量管控:通過在各個層級建立數據清洗、轉換和驗證的規則,確保數據在向上層流動的過程中質量得到逐層提升,最終輸出高質量、可信的數據。
- 提升處理效率與復用性:分層架構避免了重復計算。下層加工的通用數據結果可以被多個上層應用復用,減少了資源浪費,提升了整體處理效率。
- 增強靈活性與可擴展性:各層之間解耦,當業務需求變化或需要引入新的數據源時,可以獨立地對某一層進行修改或擴展,而無需牽動整個體系。
- 簡化數據溯源與運維:清晰的分層使得數據血緣關系一目了然,當數據出現問題時,可以快速定位到問題發生的具體層級,便于故障排查和影響范圍評估。
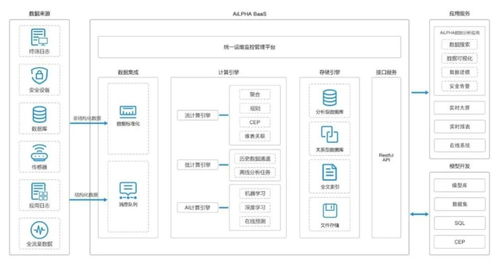
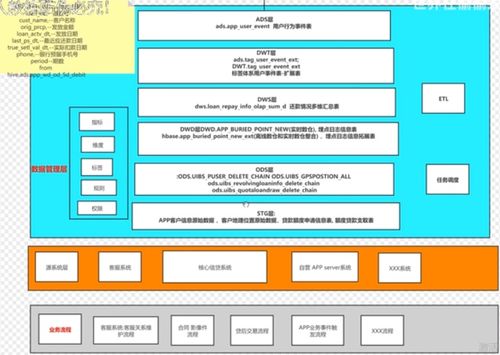
典型的分層架構及各層詳解
一個經典的數據倉庫分層通常包含以下核心層級(具體命名可能因企業而異):
1. 數據采集層
- 作用:這是數據進入數據倉庫的起點,主要負責從各種異構數據源(如業務數據庫、日志文件、第三方API、物聯網設備等)中抽取、加載數據。
- 核心任務:
- 數據抽取:以增量或全量的方式,定時或實時地從源系統獲取數據。
- 數據加載:將抽取的原始數據幾乎不做處理地存儲到數據倉庫的底層存儲中,因此這一層的數據也稱為“操作數據存儲”或“貼源數據層”。
- 格式統一:可能進行簡單的格式標準化,但核心是保留數據的原始狀態,便于后續問題回溯。
2. 數據存儲與分析核心層
這一部分是數據倉庫的“心臟”,通常進一步細分為:
- 明細數據層:
- 對采集層的原始數據進行清洗、轉換、集成和規范化。例如,統一字段格式、處理空值、關聯多表數據形成寬表、遵循一致的業務規則等。
- 此層的數據是面向主題的、干凈的、粒度的明細數據,是后續所有數據加工的單一可信來源。
- 匯總數據層 / 服務數據層:
- 基于明細數據層,根據具體的業務分析需求,進行輕度或高度的匯總、聚合。例如,生成日/月銷量報表、用戶行為畫像寬表、部門級KPI指標等。
- 這一層的數據已經過深度加工,查詢性能高,旨在直接支持數據應用、報表和即席分析,因此也常被稱為“數據集市”。
3. 數據處理和存儲支持服務
這不是一個獨立的分層,而是貫穿整個架構的支撐體系:
- 數據處理服務:指執行數據清洗、轉換、聚合等任務的計算引擎(如Apache Spark, Flink, Hive, Tez等)及其調度管理系統(如Apache Airflow, DolphinScheduler等)。它們負責驅動數據在各層之間按既定邏輯和計劃流動。
- 數據存儲服務:指各層數據物理存儲的介質和技術選型。例如,采集層和明細層可能使用HDFS、對象存儲或低成本分布式數據庫來存儲海量原始數據;匯總層和應用層則可能使用MPP數據庫、云數據倉庫或OLAP引擎(如ClickHouse, StarRocks)來提供高性能查詢。
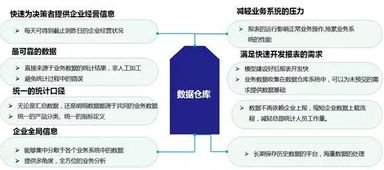
數倉分層帶來的核心好處
采用分層架構的數據倉庫帶來了多重收益:
- 對業務:能夠快速、靈活地響應多變的業務分析需求,提供及時、準確的數據洞察,支撐決策。
- 對技術:構建了標準化的數據處理流水線,提升了開發效率、資源利用率和系統穩定性,降低了長期維護成本。
- 對數據本身:建立了從原始數據到可信數據資產的規范化生產流程,保障了數據的一致性、準確性和安全性,使數據真正成為企業的核心資產。
通過清晰的數據倉庫分層架構,企業能夠將雜亂無章的數據流,梳理成一條條高效、可控的數據生產線,源源不斷地為智能決策和業務創新輸送“高質量燃料”。
如若轉載,請注明出處:http://www.theaddress.cn/product/66.html
更新時間:2026-01-16 15:54:07